OpenAI just published a paper that explains how to read the "black box." ChatGPT can answer questions, but even its creators couldn’t explain why it picks a specific word. That opacity blocks AI from high-stakes domains.
Imagine a hospital using AI. A patient dies. Lawyers ask why the model misdiagnosed. The old answer: we don’t know. That’s unacceptable for medicine, finance, or autonomous systems.
OpenAI trained models where 99.9% of the connections are zero—only 0.1% matter. Instead of hurting performance, sparsity exposes purpose. Every remaining connection exists for a reason.
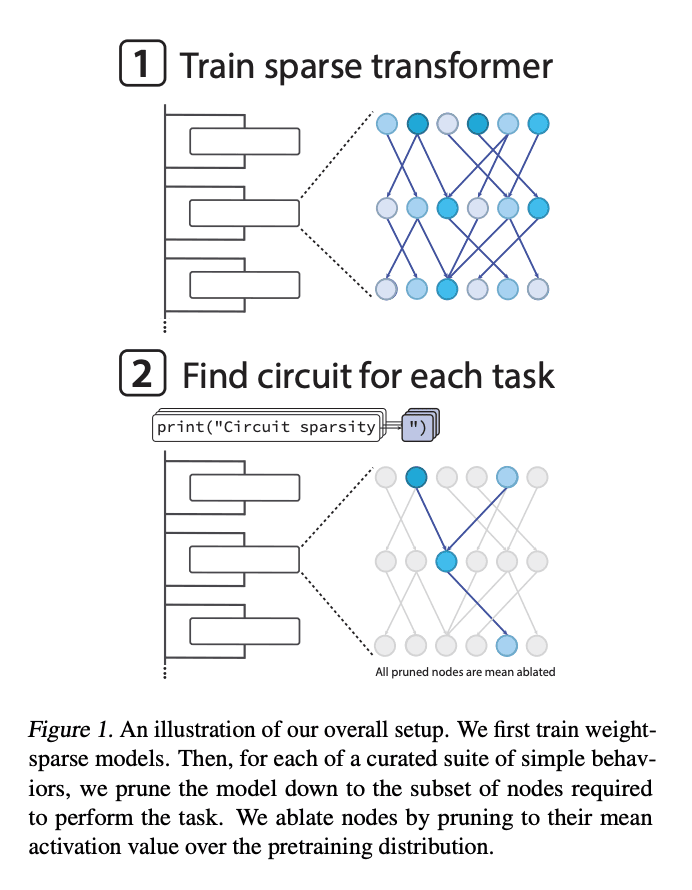
They mapped tiny circuits, some with just 12 components and 9 connections, and explained precisely what each part does. One circuit handles quote closure: an MLP detects quote type, an attention head copies the correct closing character.
They validated necessity and sufficiency. Remove any node in the circuit and performance collapses. Remove the rest of the model and keep the circuit—task performance still holds. Each circuit is the behavior.
Because they understand the circuits, they can craft adversarial attacks intentionally. Transparency creates control. You can see which node failed and why.
This is the unlock for regulated industries. With auditable circuits, hospitals, banks, and regulators can trust AI decisions—or at least inspect them when they go wrong.
The bigger idea: interpretability isn’t a side quest. Sparse, understandable networks may be how AI graduates from experimental to essential infrastructure.