Recent research from the Chinese company Kimi introduces a subtle but potentially important architectural improvement in transformer models. While the idea is conceptually simple, its implications could meaningfully impact how large-scale AI systems are trained and deployed.
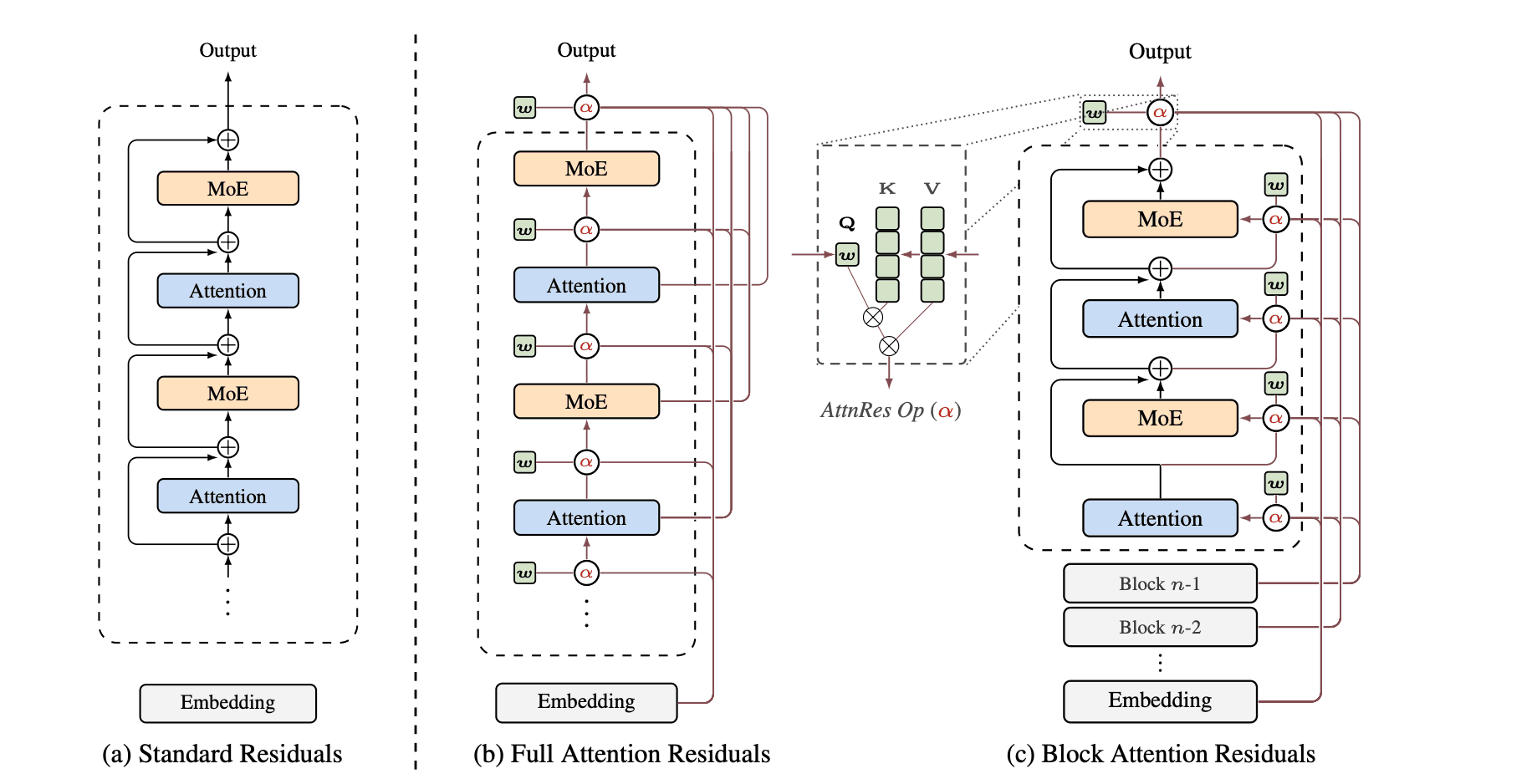
To understand the contribution, it helps to revisit how modern transformer models operate. Transformers rely on attention mechanisms to determine which input tokens are most relevant when producing outputs. This design has been foundational to the success of large language models. However, while attention is applied extensively across tokens, the same level of flexibility has not traditionally been applied across the depth of the network.
Modern models are often extremely deep, consisting of dozens or even hundreds of stacked layers. Communication between these layers is typically handled through residual connections, where each layer adds its output to the accumulated representation from previous layers. Over time, this process creates a blended internal state that contains information from all earlier computations.
While effective, this approach has limitations. As signals propagate through many layers, early representations can become diluted. The model has limited ability to explicitly select which intermediate states remain important, leading to inefficiencies in how information is preserved and reused.
The Kimi researchers propose a straightforward modification. Instead of each layer relying primarily on the immediately preceding layer, they allow layers to attend to outputs from any previous layer. In effect, this introduces an attention mechanism over the model’s own depth.
This means a deeper layer is no longer constrained to incremental updates. It can directly retrieve and reuse representations from earlier stages if those are more informative. For example, a later layer may determine that a representation formed much earlier in the network is more useful than recent transformations and selectively incorporate it.
This idea extends the core principle of attention beyond tokens to the structure of the network itself. Just as transformers learn which words matter, they can now learn which layers matter.
Empirically, the results are notable. The proposed method achieves approximately 1.25 times greater compute efficiency while introducing less than four percent additional training overhead on a 48 billion parameter model. Performance improvements are also observed on reasoning benchmarks, including a gain of 7.5 points on GPQA-Diamond.
What makes this development particularly interesting is its simplicity. Rather than introducing an entirely new architecture, it refines an existing one by giving the model more control over how it accesses its own internal representations.
Historically, many of the most impactful advances in deep learning have followed this pattern. Small structural adjustments, when aligned with the right inductive biases, can lead to disproportionately large gains in efficiency and capability.
Transformers originally reshaped AI by applying attention across tokens. This work suggests a natural next step: applying attention across layers. As models continue to scale, mechanisms that improve how information is reused and prioritized within deep networks may become increasingly important.
This direction reflects a broader trend in the field. Progress is no longer driven solely by scale, but by more efficient and flexible ways of organizing computation within large models.